
단위테스트 책을 읽고 실습 하며 내용을 정리한 글입니다. 학습 과정에서 작성된 글이기 때문에 잘못된 내용이 있을 수 있으며, 이에 대한 지적이나 피드백은 언제든 환영입니다.

1. 단위 테스트 세 가지 스타일
단위 테스트에서 출력 기반 테스트, 상태 기반 테스트, 통신 기반 테스트 세 가지가 존재합니다. 하나의 테스트에서는 하나 또는 둘, 세 가지 스타일 모두를 함께 사용할 수도 있는데 이에 대해 살펴보겠습니다.
1-1. 출력 기반 테스트
테스트 대상 시스템(SUT)에 입력을 넣고 생성되는 출력을 점검하는 방식입니다. 단위 테스트 스타일은 전역 상태나 내부 상태를 변경하지 않는 코드에만 적용되므로 반환 값만 검증하면 됩니다. 이는 함수형(Functional)이라고도 하며 부작용이 없는 코드 선호를 강조합니다.
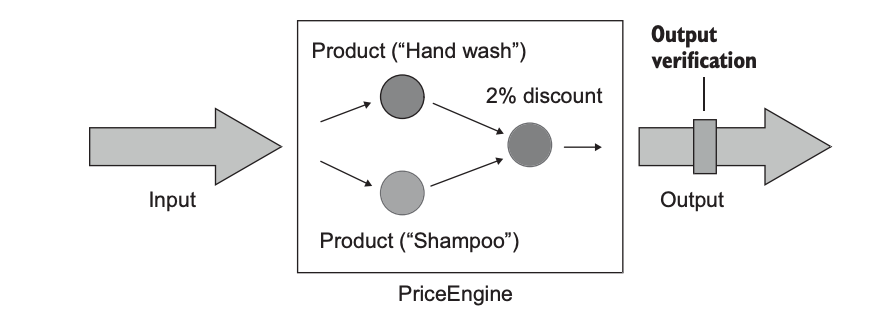
1-2. 상태 기반 스타일
작업이 완료된 후 시스템 상태를 확인하는 방식입니다. SUT나 협력자 중 하나 또는 데이터베이스나 파일 시스템 등과 같은 프로세스 외부 의존성의 상태 등을 의미할 수 있습니다.

1-3. 통신 기반 스타일
목을 사용해 테스트 대상 시스템과 협력자 간 통신을 검증합니다.

2. 단위 테스트 스타일 비교
좋은 단위 테스트의 4대 요소는 회귀 방지, 리팩토링 내성, 빠른 피드백, 유지 보수성입니다.
2-1. 회귀 방지와 피드백 속도 지표로 스타일 비교
회귀 방지와 피드백 속도 측면에서 출력 기반, 상태 기반, 통신 기반 테스트 세 가지 스타일을 비교해보겠습니다. 회귀 방지와 빠른 피드백 특성이 비교하기 가장 쉬운데, 회귀 방지 지표는 특정 스타일에 따라 달라지지 않기 때문입니다. 이는 세 가지 특성으로 결정됩니다.
- 테스트 중 실행되는 코드의 양
- 코드 복잡도
- 도메인 유의성
보통 실행하는 코드가 많든 적든 원하는 대로 테스트를 작성할 수 있습니다. 따라서 코드의 양은 회귀 방지와 피드백 지표에 영향을 미치진 않습니다. 아래와 같이 코드가 아무리 많더라도 하나씩 테스트를 작성하다보면 결국 어떤 결과를 가져올 지 예측하고 검증할 수 있기 때문입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
@Component
@RequiredArgsConstructor
public class PostQueryFacade {
// Single
private final PostQueryService postQueryService;
private final MemberQueryService memberQueryService;
private final CategoryQueryService categoryQueryService;
// Collections
private final ReviewQueryService reviewQueryService;
private final PostImageQueryService postImageQueryService;
private final ReviewImageQueryService reviewImageQueryService;
// MongoDB
private final MongoDBPostQueryService mongoDBPostQueryService;
private final MongoDBPostCommandService mongoDBPostCommandService;
private final DocumentMapper documentMapper;
public PostResponse findPostById(Long postId) {
PostDocument document = mongoDBPostQueryService.findPostDocumentByPostId(postId);
if (nonNull(document)) {
return PostResponse.of(document);
}
upsertPost(postId);
PostDocument savedPostDocument = mongoDBPostQueryService.findPostDocumentByPostId(postId);
return PostResponse.of(savedPostDocument);
}
@Transactional
public void upsertPost(Long postId) {
Post findPost = postQueryService.findPostById(postId);
Member findWriter = memberQueryService.findMemberById(findPost.getMemberId());
ConcreteCategory findCategory = categoryQueryService.findConcreteCategoryByPostId(
findPost.getConcreteCategoryId()
);
List<Review> findReviews = reviewQueryService.findReviewsByPostId(postId);
List<PostImage> findPostImages = postImageQueryService.findReviewImagesByPostId(postId);
List<ReviewImage> findReviewImages = reviewImageQueryService.findReviewImagesByPostId(postId);
PostDocument postDocument = PostDocument.from(
findPost,
documentMapper.convertMemberToDocument(findWriter),
documentMapper.convertCategoryToDocument(findCategory),
documentMapper.convertReviewsToDocument(findReviews, findReviewImages),
documentMapper.convertPostImageToDocument(findPostImages)
);
mongoDBPostCommandService.save(postId, postDocument);
}
}
코드 복잡도와 도메인 유의성 역시 마찬가지입니다. 단, 통신 기반 스타일에는 예외가 하나 있는데 SUT를 테스트하면서 작은 코드 조각을 검증하고 다른 것은 모두 목을 사용하는 것입니다. 이는 피상적인 테스트가 될 수 있기 때문에 이 부분에서는 코드가 복잡하더라도 정확한 결과를 검증하는 것이 중요합니다. 하지만 이는 통신 기반 테스트의 결정적인 특징이 아닌 목을 남용하는 극단적 사례입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
@SpringBootTest
@ActiveProfiles("test")
@AutoConfigureMockMvc
class UserCommandControllerTest {
@InjectMocks
private UserCommandController userCommandController;
@Mock
private UserService userService;
/**
* 목을 사용하면 해당 대역이 대체되기 때문에 정확한 결과 검증이 어려울 수 있습니다.
* 따라서 가급적 목 사용은 최소화하며 실제 환경과 유사하게 테스트를 진행합니다.
* */
@Autowired
private MockMvc mockMvc;
@Autowired
private ObjectMapper objectMapper;
@Test
@DisplayName("Mocking을 하게 되면 원하는 결과 값이 반환된다.")
void Mocking_Gives_Wanted_Result() throws Exception {
// given
UserSignupRequest request = new UserSignupRequest("devjun");
User newUser = new User("devjun");
User result = new User(1L, "devjun");
UserSignupResponse response = new UserSignupResponse(result);
doReturn(result)
.when(userService).save(newUser);
// when
ResultActions resultActions = mockMvc.perform(post("/api/users")
.contentType(MediaType.APPLICATION_JSON)
.content(objectMapper.writeValueAsString(request))
);
// then
resultActions.andExpect(status().isOk())
.andExpect(jsonPath("userId", response.getUserId()).exists())
.andDo(print());
}
}
마지막으로 테스트 스타일과 테스트 피드백 속도 사이에도 상관관계가 거의 없습니다. 테스트가 프로세스 외부 의존성과 떨어져 단위 테스트 영역에 있는 한 모든 스타일은 테스트 실행 속도가 거의 동일합니다. 목은 런타임에 지연 시간이 생기는 편이기 때문에 통신 기반 테스트가 약간 나쁠 수는 있지만 이러한 테스트가 수만 개 수준이 아니라면 사실상 별다른 차이가 없습니다.
이를 정리해보면 테스트 중 실행되는 코드의 양이나 코드 복잡도, 도메인 유의성은 좋은 테스트의 지표 중 회귀 방지, 빠른 피드백 지표에 영향을 거의 미치지 않습니다.
2-2. 리팩토링 내성 지표로 스타일 비교하기
리팩토링 내성 지표와 관련해서는 상황이 다릅니다. 리팩토링 내성은 리팩토링 중 발생하는 거짓 양성(허위 경보) 수에 대한 척도입니다. 결국 거짓 양성은 식별할 수 있는 동작이 아니라 코드의 구현 세부 사항에 결합된 테스트의 결과입니다. 출력 기반 테스트는 테스트가 테스트 대상 메서드에만 결합되므로 거짓 양성 방지가 가장 우수합니다. 이러한 테스트가 구현 세부 사항에 결합하는 경우는 테스트 대상 메서드가 구현 세부 사항일 뿐입니다.
즉 아래와 같이 출력 기반 테스트는 구현 세부사항이 결합 돼 있더라도 인자에 따른 최종 결과만 검증하기 때문에 결과만 바로 알 수 있으며, 이를 통해 거짓 양성 방지가 우수합니다. 또한 입력으로 부터의 결과만 검증하기 때문에 코드를 리팩토링하더라도 핵심 로직은 영향을 잘 받지 않습니다.
1
2
3
4
5
6
@FunctionalInterface
public interface Calculator {
int add(int x, int y);
}
1
2
3
4
5
6
7
8
9
10
11
12
@DisplayName("정수 더하기 테스트")
class CalculatorTest {
private Calculator calculator = Integer::sum;
@Test
@DisplayName("두 정수를 더하면 원하는 값이 출력된다.")
void 두_수_더하기_테스트() {
int expected = 3;
assertEquals(expected, calculator.add(1, 2));
}
}
반면 상태 기반 테스트는 일반적으로 거짓 양성이 되기 쉽습니다. 이러한 테스트는 테스트 대상 메서드 외에도 클래스 상태와 함께 작동하기 때문입니다. 테스트와 제품 코드 간의 결합도가 클수록 유출되는 구현 세부 사항에 테스트가 얽매일 가능성이 커지는데, 상태 기반 테스트는 큰 API 노출 영역에 의존하므로 구현 세부 사항과 결합할 가능성이 높습니다. 예를 들어 CGV로부터 최신 영화 목록을 받아온 후 데이터베이스에 저장하는 API가 있다고 가정해보겠습니다. 이 경우 CGV로부터 받는 영화 결과와 데이터베이스의 상태에 영향을 받기 때문에 이에 대한 테스트는 조금 더 까다롭고 거짓 양성을 보일 확률도 큽니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
@RestController
@RequiredArgsConstructor
@RequestMapping("/api/movies/command")
public class MovieCommandController {
private final CGVRestClient moviesRestClient;
private final MovieCommandService movieCommandService;
@PostMapping("/recently-released-movies")
public ResponseEntity<List<MovieResponse>> saveRecentlyReleasedMovies() {
List<MovieResponse> response = moviesRestClient.retrieveAllMovies();
List<Movie> movies = convertToMovies(response);
movieCommandService.saveAll(movies);
return ResponseEntity.ok(response);
}
}
마지막으로 통신 기반 테스트가 허위 경보에 가장 취약합니다. 테스트 대역으로 상호 작용을 확인하는 테스트는 대부분 깨지기 쉽기 때문입니다. 이는 스텁과 상호 작용하는 경우에 자주 나타나는데, 이러한 상호 작용을 확인해서는 안됩니다. 애플리케이션 경계를 넘는 상호 작용에서만 이를 확인하고 해당 상호 작용의 부작용이 외부 환경에 보이는 경우에만 목을 사용합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
@TestPropertySource(
properties = {"movieapp.baseUrl=http://localhost:${wiremock.server.port}/all-movies"}
)
@AutoConfigureWireMock(port = 0)
@DisplayName("영화 목록조회 스터빙 테스트")
class MovieRetrieveAllStubbingTest extends AbstractTestConfiguration {
@BeforeAll
static void beforeAll() throws IOException {
// 목으로 일정한 결과를 반환
MoviesStub.setStub();
}
@Autowired
private CGVRestClient cgvRestClient;
@Test
@DisplayName("영화 리스트를 스터빙했을때 all-movies.json 파일 내부의 결과 값이 반환된다.")
void 영화_리스트_스터빙_URL_EQUALTO_테스트() {
// when
List<MovieResponse> response = cgvRestClient.retrieveAllMovies();
// then
Assertions.assertTrue(response.size() == 10);
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
public final class MovieStubOrder {
/**
* 영화 목록을 CGV로 부터 받아오기 위해서는 해당 대역이 일정한 결과를 반환하도록 해야하며
* 이와 같이 애플리케이션의 경계를 넘는 경우에만 목을 사용해줍니다.
*/
public static void setStub() {
stubFor(get(urlPathMatching("/cgv/movies/1"))
.atPriority(1)
.willReturn(WireMock.aResponse()
.withStatus(HttpStatus.OK.value())
.withHeader(HttpHeaders.CONTENT_TYPE, MediaType.APPLICATION_JSON_VALUE)
.withBodyFile("movie.json")));
}
}
리팩토링 내성을 잘 지키려면 통신 기반 테스트를 사용할 때 더 신중해야 합니다. 그러나 피상적인 테스트가 통신 기반 테스트의 결정적인 특징이 아닌 것처럼 불안정성도 통신 기반 테스트의 결정적인 특성이 아닙니다. 캡슐화를 잘 지키고 테스트를 식별할 수 있는 동작에만 결합하면 거짓 양성을 최소로 줄일 수 있습니다. 물론 단위 테스트 스타일에 따라 필요한 노력도 다릅니다.
2-3. 유지 보수성 지표로 스타일 비교하기
마지막으로 유지 보수성 지표는 테스트 스타일과 밀접한 관련이 있습니다. 그러나 리팩토링 내성과 달리 완화할 수 있는 방법이 많지는 않습니다. 유지 보수성은 단위 테스트의 유지비를 측정하며 두 가지 특성으로 정의합니다. 테스트가 크면 필요할 때 파악하기도 변경하기도 어려우므로 유지 보수가 쉽지 않습니다. 마찬가지로 하나 이상의 프로세스 외부 의존성과 직접 작동하는 테스트는 데이터베이스 서버 재부팅, 네트워크 연결 문제 해결 등과 같이 운영하는 데 시간이 필요하므로 유지 보수가 어렵습니다.
- 테스트를 이해하기 얼마나 어려운가?
- 테스트를 실행하기 얼마나 어려운가?
다른 두 가지 스타일과 비교하면 출력 기반 테스트가 가장 유지 보수하기가 용이합니다. 출력 기반 테스트는 거의 항상 짧고 간결하기 때문입니다. 이러한 이점은 메서드로 입력을 공급하는 것과 해당 출력을 검증하는 두 가지로 요약할 수 있다는 사실에서 비롯됩니다. 출력 기반 테스트의 기반 코드는 전역 상태나 내부 상태를 변경할 리 없으므로 프로세스 외부 의존성을 다루지 않으며, 따라서 두 가지 유지 보수성 모두의 측면에서 출력 기반 테스트가 가장 좋습니다.
1
2
3
4
5
6
@FunctionalInterface
public interface Calculator {
int add(int x, int y);
}
1
2
3
4
5
6
7
8
9
10
11
12
13
@DisplayName("정수 더하기 테스트")
class CalculatorTest {
private Calculator calculator = Integer::sum;
@Test
@DisplayName("두 정수를 더하면 원하는 값이 출력된다.")
void 두_수_더하기_테스트() {
int expected = 3;
assertEquals(expected, calculator.add(1, 2));
}
}
상태 기반 테스트는 일반적으로 출력 기반 테스트보다 유지 보수가 쉽지 않습니다. 상태 검증은 종종 출력 검증보다 더 많은 공간을 차지하기 때문입니다. 또한 훨씬 많은 데이터를 확인해야 하므로 크기가 대폭 커질 수도 있습니다. 대부분 테스트를 단축하는 헬퍼 메서드로 문제를 완화할 수도 있지만 이러한 메서드를 작성하고 유지하는 데 상당한 노력이 필요합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
@DataJpaTest
@ActiveProfiles("test")
@Import(UserDomainConverter.class)
@DisplayName("도메인 모델 컨버터 테스트")
@AutoConfigureTestDatabase(replace = AutoConfigureTestDatabase.Replace.NONE)
class ConverterTest {
@Autowired
private UserJpaRepository userJpaRepository;
@Test
@DisplayName("엔티티를 도메인모델로 변환할 수 있다.")
void 엔티티_도메인모델_변환_테스트() {
// given
User user = new User("devjun10");
// when
User user = userJpaRepository.save(user);
// then
Assertions.assertEquals(1L, user.getId());
Assertions.assertEquals("devjun10", user.getName());
Assertions.assertEquals("2023-01-02", user.getCreatedAt());
Assertions.assertNull(user.getLastModifiedAt());
......
}
}
상태 기반 테스트를 단축하는 또 다른 방법으로 검증 대상 클래스의 동등 멤버를 정의할 수 있습니다. 이는 개별 속성을 지정하지 않고 값 객체를 통해 비교하는 것인데 이를 통해 컬렉션을 비교할 수도 있습니다. 이는 강력한 기술이지만 본질적으로 클래스가 값에 해당하고 값 객체로 변환할 수 있을 때만 효과적입니다. 그렇지 않으면 코드 오염으로 이어집니다. 이 두 가지 기법(헬퍼 메서드, 값 객체)은 가끔만 적용할 수 있으며, 이러한 기법을 적용할 수 있더라도 상태 기반 테스트는 출력 기반 테스트보다 공간을 더 많이 차지하므로 유지 보수성이 떨어집니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
@Entity
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
......
/**
* equals & hashcode를 재정의하면 컬렉션 내부에서
* 이 값을 기준으로 객체를 비교합니다.
* */
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (!(o instanceof User user)) return false;
return getId().equals(user.getId());
}
@Override
public int hashCode() {
return Objects.hash(getId());
}
@Override
public String toString() {
return id.toString();
}
}
통신 기반 테스트는 유지 보수성 지표에서 출력 기반 테스트와 상태 기반 테스트보다 점수가 낮습니다. 통신 기반 테스트에는 테스트 대역과 상호 작용 검증을 설정해야 하며, 이는 공간을 많이 차지합니다. 목이 사슬(mock chain) 형태로 있을 때 테스트는 더 커지고 유지 보수하기 어려워집니다.
목 사슬(mock chain)이란 목이 다른 목을 반환하고 그 다른 목은 또 다른 목을 반환하는 식으로 여러 계층이 있는 목이나 스텁이 있을 때를 말합니다.
2-4. 결론
세 가지 스타일 모두가 회귀 방지와 피드백 속도 지표에서는 점수가 같습니다. 하지만 이 중 출력 기반 테스트가 가장 결과가 좋은데 이 스타일은 구현 세부 사항과 거의 결합되지 않기 때문에 리팩토링 내성을 적절하게 유지하고자 주의를 많이 기울일 필요가 없기 때문입니다. 이러한 테스트는 간결하고 프로세스 외부 의존성이 거의 없기 때문에 유지보수도 쉽습니다.

상태 기반 테스트와 통신 기반 테스트는 두 지표 모두 좋지 않습니다. 유출된 구현 세부 사항에 결합할 가능성이 높고 크기도 커서 유지비가 많이 들기 때문입니다. 그러므로 가능한 다른 테스트보다 출력 기반 테스트를 우선시 하도록 합니다. 물론 이는 현실적이지 않을 수도 있는데, 특히 객체지향일 경우 더욱 그렇습니다. 그래도 가능한 출력 기반의 형태로 바꿔 좋은 테스트 코드를 작성하기 위해 노력해야 합니다.
3. 함수형 아키텍처의 이해
가장 좋은 스타일인 출력 기반 테스트를 적용하기 위해 코드를 순수 함수로 만드는 것입니다. 순수 함수로 만드는 방법을 알기전 약간의 선행 지식이 필요한데 이에 대해 알아보겠습니다.
3-1. 함수형 프로그래밍
함수형 프로그래밍은 수학적 함수(Mathematical Function)을 사용한 프로그래밍입니다. 수학적 함수는 숨은 입출력이 없는 함수 또는 메서드를 의미하며 메서드명, 인자, 반환 타입으로 구성된 메서드 시그니처가 있습니다.

이는 부작용이 없으며 멱등성을 가지고 있습니다. 하지만 현실적으로 애플리케이션의 모든 부작용을 없앨 수는 없으며, 함수형 프로그래밍의 목표는 비지니스 로직을 처리하는 코드와 부작용을 일으키는 코드를 분리하는 것입니다. 이때 결정을 내리는 코드는 함수형 코어(Functional Core, 불변 코어, Immutable Core)라고 하며, 해당 결정에 따라 작용하는 코드는 가변 셸(Mutable Shell)로 부릅니다.
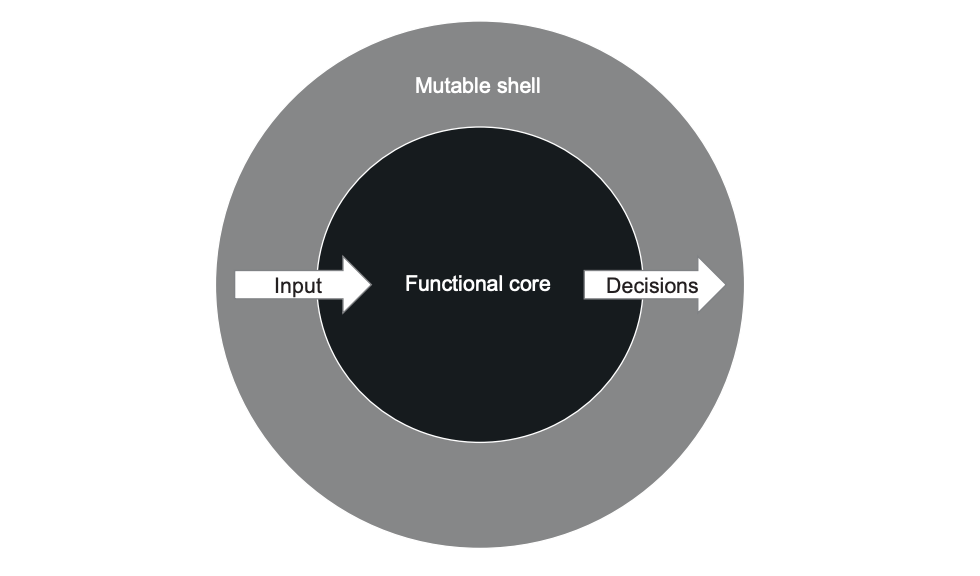
이는 코드의 핵심 로직을 함수형으로 만드는 것을 통해 함수 호출 횟수에 상관없이 주어진 입력에 대해서는 동일한 출력을 반환하는 것을 만드는 것입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
@DisplayName("정수 더하기 테스트")
class CalculatorTest {
// 호출 횟수에 상관없이 주어진 입력에 대해서는 테스트를 반복하더라도 동일한 결과가 나옵니다.
private Calculator calculator = Integer::sum;
@Test
@DisplayName("두 정수를 더하면 원하는 값이 출력된다.")
void 두_수_더하기_테스트() {
int expected = 3;
Assertions.assertEquals(expected, calculator.add(1, 2));
}
}
함수형 아키텍처는 부작용을 다루는 코드를 최소화하면서 순수 함수(불변) 방식으로 작성한 코드의 양을 극대화합니다.
입출력을 명시한 수학적 함수는 이에 따르는 테스트가 짧고 간결하며 이해학소 유지 보수하기 쉬우므로 테스트하기가 매우 쉽습니다. 출력 기반 테스트를 적용 할 수 있는 메서드 유형은 수학적 함수뿐이며 이는 유지 보수성이 뛰어나고 거짓 양성 빈도가 낮아 테스트하기 쉽습니다. 숨은 입출력의 유형은 아래와 같습니다.
| 특징 | 설명 |
|---|---|
| 내외부 상태에 대한 참조 | 메서드 시그니처에 없는 실행 흐름에 대한 입력들로 숨어 있습니다. 내외부 상태에 대한 참조는 Date.now와 같이 정적 속성을 사용해 현재 날짜와 시간을 가져오는 메서드 또는 데이터베이스에 데이터를 질의하는 것이 있습니다. |
| 부작용 | 메서드 시그니처에 표시되지 않은 출력이며, 따라서 숨어있습니다. |
| 예외 | 메서드가 예외를 던지면 프로그램 흐름에 메서드 시그니처에 설정된 계약을 우회하는 경로를 만듭니다. |
메서드가 수학적 함수 인지 판별하는 가장 좋은 방법은 프로그램의 동작을 변경하지 않고 해당 메서드에 대한 호출을 반환 값으로 대체할 수 있는지 확인하는 것입니다. 메서드 호출을 해당 값으로 바꾸는 것을 참조 투명성(referential transparency)이라고 합니다.
3-2. 함수형 아키텍처와 육각형 아키텍처 비교
둘은 모두 관심사 분리라는 아이디어를 기반으로 하지만 이 분리를 둘러싼 구체적 내용은 다양합니다. 육각형 아키텍처는 도메인과 애플리케이션 서비스 계층을 구별합니다. 도메인 계층은 비즈니스 로직에 책임이 있는 반면, 애플리케이션 서비스 계층은 데이터베이스나 SMTP 서비스와 같이 외부 애플리케이션과의 통신에 책임이 있습니다. 이는 결정과 실행을 분리하는 함수형 아키텍처와 매우 유사합니다.

또 다른 유사점은 의존성 간의 단방향 흐름이라는 점입니다. 육각형 아키텍처에서 도메인 계층 내 클래스는 서로에게만 의존해야 하며 애플리케이션 서비스 계층의 클래스에 의존해서는 안됩니다. 마찬가지로 함수형 아키텍처의 불변 코어는 가변 셸에 의존하지 않고 외부 계층과 격리돼 작동합니다. 이로 인해 함수형 아키텍처를 테스트하기 쉽운데 가변 셸에서 불변 코어를 완전히 떼어낼 셸이 제공하는 입력을 단순한 값으로 모방할 수 있기 때문입니다.

이 둘의 차이점은 부작용에 대한 처리에 있습니다. 함수형 아키텍처는 모든 부작용을 불변 코어에서 비즈니스 연산 가장자리로 밀어내며, 이 가장자리는 가변 셸이 처리합니다. 반면 육각형 아키텍처는 도메인 계층에 제한하는 한 도메인 계층으로 인한 부작용도 문제없습니다. 육각형 아키텍처의 모든 수정 사항은 도메인 계층 내에 있어야 하며 계층의 경계를 넘어서는 안되는데, 예를 들어 도메인 클래스 인스턴스는 데이터베이스에 직접 저장할 수 없지만, 상태는 변경할 수 있습니다. 애플리케이션 서비스에서 이 변경 사항을 데이터베이스에 적용합니다.
함수형 아키텍처는 육각형 아키텍처의 하위 집합입니다. 극단적으로는 함수형 아키텍처를 육각형 아키텍처로 볼 수 있습니다.
4. 함수형 아키텍처와 출력 기반 테스트 예제
테스트를 정확하게 하기 위해서는 출력기반 스타일에 적응해야 하는데, 이를 위해 출력 기반 테스트 스타일 예제를 살펴보겠습니다.
- 프로세스 외부 의존성에서 목으로 변경
- 목에서 함수형 아키텍처로 변경
아래는 파일 경로와 파일 경로와 이름을 입력받아 사과는 빨간색 과일이다. 라는 문장을 딸기는 빨간색 과일이다. 로 치환하는 예제입니다. 여기서 핵심은 사과를 딸기로 치환하는 부분입니다. 이를 함수형 코어로 만들어 줍니다.
1
2
3
4
5
6
@FunctionalInterface
public interface WordConvertor {
String convert(String content);
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
public class ContentConvertor {
private static final String APPLE = "사과";
private static final String STRAWBERRY = "딸기";
private final FileReader fileReader;
private final WordConvertor wordConvertor;
public ContentConvertor(FileReader fileReader) {
this.fileReader = fileReader;
this.wordConvertor = (content -> content.replaceAll(APPLE, STRAWBERRY));
}
public String getContent() {
return fileReader.getContent();
}
public String convertWord() {
return wordConvertor.convert(getContent());
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
public class FileReader {
private final String path;
private final String fileName;
public FileReader(String path, String fileName) {
this.path = path;
this.fileName = fileName;
}
public String getPath() {
return path;
}
public String getFileName() {
return fileName;
}
public String getContent() {
try {
Path filePath = Paths.get(path + fileName);
return String.join("", Files.readAllLines(filePath));
} catch (Exception e) {
throw new IllegalArgumentException("올바르지 않은 파일 정보입니다.");
}
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (!(o instanceof FileReader that)) return false;
return getPath().equals(that.getPath()) && getFileName().equals(that.getFileName());
}
@Override
public int hashCode() {
return Objects.hash(getPath(), getFileName());
}
@Override
public String toString() {
return String.format("Path: %s, Name: %s", path, fileName);
}
}
이렇게 되면 함수형 코어로 된 핵심 부분을 테스트 하기 위해서는 아래와 같은 테스트코드를 작성하면 됩니다. 인자에 따른 결과 값을 명확히 알 수 있으며, 멱등성이 보장 돼서 정확한 테스트를 할 수 있습니다. 적어도 테스트에서는 가급적 함수형을 지향하는 것이 그만큼 좋습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
@DisplayName("문장 변환 테스트")
class ConvertorTest {
@Test
@DisplayName("올바른 파일 경로와 이름을 넣으면 사과를 딸기로 치환한 문장을 반환한다.")
void 문장_변환_테스트() {
String path = "/path/";
String fileName = "txt.txt";
FileReader fileReader = new FileReader(path, fileName);
ContentConvertor convertor = new ContentConvertor(fileReader);
Assertions.assertEquals("딸기는 빨간색 과일이다.", convertor.convertWord());
}
}
5. 함수형 아키텍처의 단점
함수형 아키텍처를 항상 구성할 수는 없습니다. 또한 함수형 아키텍처라고해도 코드베이스가 커지고 성능에 영향을 미치면서 유지 보수성의 이점이 상쇄될 수 있습니다. 기존 코드와 성능을 고려하면서 적충하는 것이 필요합니다.
5-1. 성능
시스템 전체에 영향을 미치는 성능은 함수형 아키텍처의 논쟁거리입니다. 문제가 되는 것은 테스트 성능이 아닙니다. 출력 기반 테스트는 목을 사용한 테스트만큼 빠르게 동작합니다. 시스템은 프로세스 외부 의존성을 더 많이 호출하고 그 결과로 성능이 떨어지는 것이 문제입니다. 즉 아래와 같이 파란색 외부 의존성을 대역을 대체하면서 걸리는 시간이 더 많은 것입니다.
함수형 아키텍처와 전통적 아키텍처 사이의 선택은 성능과 코드 유지 보수성 간의 절충입니다. 성능 영향이 그다지 눈에 띄지 않는 일부 시스템에서는 함수형 아키텍처를 사용해 유지 보수성을 향상시키는 편이 나으며, 다른 경우라면 반대로 선택해야 할 수도 있습니다. [그림 출처]
5-2. 코듭 베이스 크기 증가
코드베이스의 크기도 마찬가지입니다. 함수형 아키텍처는 함수형 코어와 가변 셸 사이를 명확하게 분리해야 합니다. 궁극적으로 코드 복잡도가 낮아지고 유지 보수성이 향상되지만 초기에 해야할 작업이 더 많을 수도 있습니다. 그러나 모든 프로젝트에 초기 투자가 타당할 만큼 복잡도가 높은 것은 아닙니다. 어떤 코드베이스는 너무 단순하거나 비즈니스 관점에서 그다지 중요하지 않습니다. 결코 초기 투자로 성과를 내지 못하기 때문에 이러한 프로젝트에서 함수형 아키텍처를 사용하는 것은 별 의미가 없습니다. 항상 시스템의 복잡도와 중요성을 고려해 함수형 아키텍처를 전략적으로 적용합니다. 마지막으로 함수형 방식에서 순수성에 많은 비용이 든다면 순수성을 따르지 않는 것도 하나의 방법입니다. 대부분의 프로젝트에서는 모든 도메인 모델을 불변으로 할 수 없기 때문에 출력 기반 테스트에만 의존할 수는 없습니다. 대부분의 경우 출력 기반 스타일과 상태 기반 스타일을 조합하게 되며, 통신 기반 스타일을 약간 섞어도 괜찮습니다.
6. 정리
출력 기반 테스트는 SUT에 입력을 주고 출력을 확인하는 테스트 스타일입니다. 이 테스트 스타일은 숨은 입출력이 없다고 가정하고 SUT 작업의 결과는 반환하는 값뿐입니다.
상태 기반 테스트는 작업이 완료된 후의 시스템 상태를 확인합니다.
통신 기반 테스트는 목을 사용해 대상 시스템과 협력자 간의 통신을 검증합니다.
단위 테스트의 고전파는 통신 기반 스타일보다 상태 기반 스타일을 선호합니다. 런던파는 반대를 선호하며 두 분파 모두 출력 기반 테스트를 사용합니다.
출력 기반 테스트가 테스트 품질이 가장 좋습니다. 이러한 테스트는 구현 세부 사항에 거의 결합되지 않으므로 리팩토링 내성이 있습니다. 또한 작고 간결하므로 유지 보수하기도 쉽습니다.
상태 기반 테스트는 안정성을 위해 더 신중해야 합니다. 단위 테스트를 하려면 비공개 상태를 노출하지 않도록 해야 합니다. 상태 기반 테스트는 출력 기반 테스트보다 크기가 큰 편이므로 유지 보수가 쉽지 않습니다. 헬퍼 메서드와 값 객체를 사용해 유지 보수성 문제를 완화할 수도 있지만 제거할 수는 없습니다.
통신 기반 테스트도 안정성을 위해 더 신중해야 합니다. 애플리케이션 경계를 넘어서 외부 환경에 부작용이 보이는 통신만 확인합니다. 통신 기반 테스트의 유지 보수성은 출력 기반 테스트 및 상태 기반 테스트와 비교할 때 좋지 않습니다. 목은 공간을 많이 차지하는 경향이 있어서 테스트 가독성이 떨어집니다.
수학적 함수는 숨은 입출력이 없는 함수입니다. 부작용과 예외가 숨은 출력에 해당합니다. 내부 상태 또는 외부 상태에 대한 참조는 숨은 입력입니다. 수학적 함수는 명시적이므로 테스트 용이성을 높여줍니다.
함수형 프로그래밍의 목표는 비즈니스 로직과 부작용을 분리하는 기술입니다.
함수형 아키텍처는 부작용을 비즈니스 연산의 가장자리로 밀어내 분리를 이루는데 도움이 됩니다. 이 방법으로 부작용을 다루는 코드를 최소화하면서 순수 함수 방식으로 작성된 코드의 양을 최대화할 수 있습니다.
함수형 아키텍처는 모든 코드를 함수형 코어와 가변 셀이라는 두 가지 범주로 나눕니다. 가변 셸은 입력 데이터를 함수형 코어에 공급하고 코어가 내린 결정을 부작용으로 변환합니다.
함수형 아키텍처와 육각형 아키텍처의 차이는 부작용 처리에 있습니다. 함수형 아키텍처는 모든 부작용을 도메인 계층 밖으로 밀어냅니다. 이와 반대로 육각형 아키텍처는 도메인 계층에만 한정돼 있는 한은 도메인 계층에 의해 만들어진 부작용도 괜찮습니다. 극단적으로 함수형 아키텍처는 육각형 아키텍처입니다.
함수형 아키텍처와 전통적인 아키텍처 사이의 선택은 성능과 코드 유지 보수성 사이의 절충이며 함수형 아키텍처는 유지 보수성 향상을 위해 성능을 희생합니다.
모든 코드베이스를 함수형 아키텍처로 전화할 수는 없습니다. 함수형 아키텍처를 전략적으로 적용하며, 이때 시스템의 복잡도와 중요도를 고려합니다. 코드베이스가 단순하거나 그렇게 중요하지 않으면 함수형 아키텍처에 필요한 초기 투자는 별 효과가 없습니다.