
글을 작성하게 된 계기
프로젝트에서 JPA를 사용하며 느꼈던 단점을 정리하기 위해 글을 작성하게 되었습니다. 크게 데이터베이스와 반대되는 사상, 복잡성과 추가쿼리, 자동화, JPA에 대한 의존성 정도가 있었는데요, 이를 하나씩 살펴보겠습니다. 기술을 사용하며 느꼈던 점이기 때문에 저런 시각으로 볼 수도 있구나 정도로 이해해 주시기 바랍니다.
1. 러닝커브, 패러다임의 불일치
JPA는 꽤 높은 러닝 커브가 존재하는데, 가장 큰 이유는 관계형 데이터베이스와 객체지향적 사상의 패러다임이 다르기 때문입니다. 관계형 데이터베이스는 데이터를 중심으로 사고하는 반면, 객체지향은 객체를 중심으로 설계됩니다. JPA는 패러다임이 다른 둘을 연결하기 위해 존재하는데, 그 과정에서 개발자가 알아야 할 개념, 용어 등이 많아 학습 곡선이 높아지게 됩니다. 이를 조금 더 상세히 살펴보겠습니다.
1-1. 패러다임의 차이
관계형 데이터베이스는 데이터를 중복 없이, 효율적으로 관리하기 위해 데이터를 테이블, 행, 열의 형태로 구조화하여 관리하며, 데이터 간의 관계는 외래 키를 통해 연결됩니다.

반면 객체 지향에서는 실세계의 개체를 객체라는 단위로 표현하며, 이 객체들은 참조를 통해 상호작용하며 프로그램의 기능을 수행합니다. 각 객체는 논리적 단위로 구성되어 있으며 자신만의 역할과 책임을 가집니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
class Post constructor(
val userId: Long,
private var _placeId: Long,
private var _districtId: Long,
private var _categoryId: Long,
private var _title: PostTitle,
private var _content: PostContent,
private var _receiptImageUrl: ImageUrl,
private var _point: Point,
) {
......
// 게시글은 자신과 연관된 제목에 대해 이를 수정하는 역할/책임을 가진다.
fun updateTitle(title: String) {
this.title.update(title)
}
// 내가 하지 못하는 권한과 같은 역할/권한은 다른 객체에게 위임해서 처리한다.
fun isWrittenBy(jmUser: JMUser): Boolean {
if (isAdmin(jmUser)) {
return true
}
return this.baseInformation.isOwner(jmUser.userId)
}
......
}
JPA는 이런 두 패러다임의 차이를 좁히고 연결하는 중간 다리 역할을 하는데, 이 과정에서 객체의 상속/연관 관계를 데이터베이스의 테이블과 어떻게 매핑 할지, 데이터 로딩 전략 을 어떻게 설정할지 등과 같은 복잡한 문제를 해결합니다. 이는 연관 관계, 매핑 전략 등으로 불리는데, JPA를 사용하기 위해서는 관계형 데이터베이스에 사용된 개념이 JPA의 어떤 개념과 연관 되는지, 동작 원리는 어떻게 되는지 등을 잘 알아야 합니다. 패러다임의 차이를 이해하면서요.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
@Entity(name = "post")
class PostJpaEntity(
@Id
@Column(name = "post_id")
@GeneratedValue(strategy = GenerationType.IDENTITY)
private var _postId: Long? = null,
......
) : BaseEntity() {
// 일대 다 관계 또한 데이터베이스에서 존재하지 않는, JPA에만 존재하는 개념으로 학습이 필요합니다.
@OneToMany(mappedBy = "post")
private var _postHashtags: Set<PostHashtagJpaEntity>? = mutableSetOf()
또한 JPA의 영속성, 트랜잭션 범위와 같은 개념에 대해서도 추가적인 학습이 필요합니다.
1-2. 문제 해결 방식의 차이
둘은 문제를 해결하는 방식 또한 다릅니다. 데이터베이스는 데이터를 기준으로 생각하기 때문에 데이터에 맞추어 객체를 모델링하며, 쿼리 를 통해 문제를 해결합니다. 즉 데이터를 조회하고, 조회한 데이터의 상태를 바꾸어 이를 데이터베이스에 반영하는 것 에 초점이 맞추어져 있습니다. 이 과정에서 객체는 단순히 데이터를 운반하는 역할 만 하게 되며, 문제를 해결하기 위한 데이터 덩어리 그 이상도 이하도 아니게 됩니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
@Service
class UserService(
private val userDao: UserDao
) {
......
fun update(
userId: Long,
nickname: String
) {
// 데이터 조회
val userExistence = userDao.findById(userId)
// 데이터 체크 및 상태 변경
userExistence?.let {
userDao.update(userId, nickname)
} ?: throw IllegalArgumentException("User with ID $userId not found")
}
......
}
/**
* 객체는 아무런 역할과 책임도 가지지 않으며, 데이터 운반을 위한
* 단순한 데이터 덩어리로 전락한다.
*/
data class UserExistence(
val userId: Long,
val nickname: String
)
반면 객체지향은 객체를 단순한 데이터 덩어리로 보지 않고 상태와 행위를 가지는 논리적 단위로 봅니다. 객체를 논리적 단위로 보기 때문에 각 객체는 역할과 책임을 가지며, 자신과 관련된 상태를 가지고 이를 처리할 수 있습니다. 객체지향에서는 이런 객체들의 조화. 즉 다른 객체들과의 협력을 통해 문제를 해결합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
class Post constructor(
val userId: Long,
private var _placeId: Long,
private var _districtId: Long,
private var _categoryId: Long,
private var _title: PostTitle,
private var _content: PostContent,
private var _receiptImageUrl: ImageUrl,
private var _point: Point,
) {
......
// 게시글은 자신과 연관된 제목에 대해 이를 수정하는 역할/책임을 가진다.
fun updateTitle(title: String) {
this.title.update(title)
}
// 내가 하지 못하는 권한과 같은 역할/권한은 다른 객체에게 위임해서 처리한다.
fun isWrittenBy(jmUser: JMUser): Boolean {
if (isAdmin(jmUser)) {
return true
}
return this.baseInformation.isOwner(jmUser.userId)
}
......
}
이를 정리해 보면, JPA를 잘 사용하기 위해서는 관계형 데이터베이스와 JPA 각각의 특징, 각 개념이 어떻게, 어떤 용어로 연결되는지 등을 모두 잘 알아야 합니다. 하나를 제대로 학습하기도 어려운데 양쪽 모두를 잘 알아야 하므로 JPA의 러닝 커브가 높으며, 이 점이 JPA의 첫 번째 단점이라 여겨졌습니다.
- Entities
- Entity Inheritance
- Managing Entities
- Querying Entities
- Further Information about Persistence
2. 복잡성과 추가쿼리
두 번째는 복잡성 과 추가쿼리 입니다. JPA를 사용하면 SQL, 쿼리를 통해 데이터를 찾을 때보다 고려할 사항이 많은데, 이에 대해 살펴보겠습니다.
2-1. 복잡성
JPA를 사용하면 Jdbc, Mybatis와 같은 데이터베이스 중심의 기술을 사용할 때보다 추가로 고려할 사항이 많습니다. 예제를 통해 살펴보겠습니다. 하나의 스터디모집 글에는 여러 개의 댓글이 달릴 수 있고, 하나의 댓글에는 여러 개의 이모티콘을 달 수 있습니다. 아래와 같은 관계에서 JPA를 사용해 한 번에 스터디, 댓글, 이모티콘 객체들을 찾아올 수 있을까요?
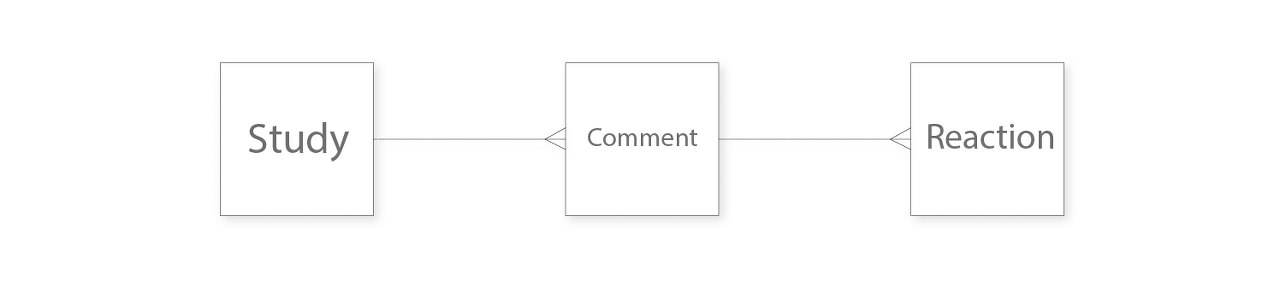
JPA를 사용해 데이터를 조회한다면 가장 먼저 페치조인(fetch join) 을 떠올릴 수 있는데, 페치조인으로 데이터를 한 번에 조회하면 MultipleBagFetchException이 발생합니다.

물론 default_batch_fetch_size, 카티션 곱을 감수한 조인, 조인 방향을 바꾸는 방식 등을 통해 원하는 객체들을 한 번에 조회할 수는 있습니다. 하지만 JPA를 사용하는 이유는 관계형 데이터베이스의 데이터를 마치 자바의 컬렉션처럼 다루게 하기 위함인데, 조인 방향성 이나 추가적인 오류 에 대한 고민이 필요하다면 일반 쿼리만 사용할 때보다 많은 케이스, 즉 복잡한 상황을 추가로 고려해야 합니다.
JPA 공식 문서를 봐도
관계형 데이터베이스의 데이터를 마치 자바의 컬렉션처럼 다루게 하기 위해 사용한다.라는 문구는 없습니다. 이는 해당 공식 문서의 맥락을 바탕으로 영한님 강의의 표현을 빌린 것입니다.
2-2. 추가쿼리
또한 JPA를 사용하면 추가쿼리 문제가 존재합니다. 아래 코드는 위에서 들었던 예제를 코드 레벨에서 구현한 것입니다. 이는 MultipleBagFetchException을 피하기 위해 게시글에서 댓글을 조회한 후, 반복문을 돌며 이모티콘을 조회하고 있는데, 이는 댓글의 개수만큼 추가 쿼리가 발생합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
@Entity(name = "post")
class PostJpaEntity(
@Id
@Column(name = "post_id")
@GeneratedValue(strategy = GenerationType.IDENTITY)
private var _postId: Long? = null,
......
) : BaseEntity() {
@OneToMany(mappedBy = "post")
private var comments: Set<CommentJpaEntity>? = mutableSetOf()
1
2
3
4
5
6
7
8
9
10
class Comment(
@Id
@Column(name = "_comment_id")
@GeneratedValue(strategy = GenerationType.IDENTITY)
private var _commentId: Long? = null,
) : BaseEntity() {
@OneToMany(mappedBy = "comments")
private var emotions: Set<EmotionJpaEntity>? = mutableSetOf()
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
@Service
class PostService(
private val postJpaRepository: PostJpaRepository
) {
@Transactional(readOnly = true)
fun findCommentsWithEmotionsByPostId(postId: Long): CommentsResponse {
val findPost = postJpaRepository.findById(postId)
val comments = findPost.comments
......
val commentsWithEmotionsResponse = mutableListOf()
for(comment in comments) {
// 추가 쿼리 발생
val emotions = comment.emotions
......
}
return CommentsResponse(comments)
}
}
만약 MyBatis나 Jdbc과 같이 조금 더 데이터베이스의 관점에서 사고할 수 있는 기술을 사용 한다면 추가 쿼리가 나가지 않기 때문에 마음껏 조인해 데이터를 조회할 수 있습니다. 데이터베이스 입장에서는 방향과 추가쿼리라는 개념 자체가 없기 때문 입니다. 하지만 JPA를 사용하면 조인 방향이나 객체 탐색 시작점, 어디까지 객체 탐색을 허용할지, 추가 쿼리는 발생하지 않는지에 대한 별도의 고려사항이 더 존재합니다.

추가쿼리 자체가 왜 나가는지는 조금만 학습하면 금방 알 수 있습니다. 하지만 추가쿼리라는 요소 때문에 조인하더라도 다른 엔티티를 사용 못 한다든지, 찾아온 데이터를 애플리케이션에서 최적화해야 한다든지, 혹은 최적화할 때도 제한요소가 있던지 등을 고려해야 합니다. 심지어 조인하더라도 여전히 추가쿼리의 문제는 존재하는데요, 일반 필드는 건드려도 상관없지만 내부에 들어있는 엔티티를 건드리는 순간 또 추가쿼리가 발생하기 때문입니다.
건드린다는건 getter 혹은 객체를 호출(toString)하는 것을 말하며, fetchJoin( )을 사용하는 경우는 이런 문제가 발생하지 않습니다. 언급한 문제는 단순 조인을 했을 경우입니다.
사실 Lazy 로딩으로 인한 추가쿼리는 데이터를 효율적으로 찾을 수 있도록 도와주며, 다음 레이어에 대한 신뢰성을 가질 수 있게 해줍니다. 굳이 객체 내부의 모든 데이터가 채워져 있지 않더라도 내가 필요한 시점에 데이터를 조회해 채울 수 있기 때문입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
@Service
class PostService(
private val postJpaRepository: PostJpaRepository
) {
@Transactional(readOnly = true)
fun findCommentsWithEmotionsByPostId(postId: Long): CommentsResponse {
val findPost = postJpaRepository.findById(postId)
val comments = findPost.comments
......
for(comment in comments) {
/**
* JPA를 사용하지 않는 경우, comment.emotions를 하면
* 추가쿼리가 나가는게 아니라 Null 값이 조회되며, 만약 이를
* 사용할 경우 NullPointException이 발생합니다.
*/
val emotions = comment.emotions
......
}
return CommentsResponse(comments)
}
}
이 덕에 다음 레이어에서는 안심하고 값을 사용하는 것에 집중할 수 있습니다. SQL문을 사용하면 데이터는 어느 시점에나 항상 채워져 있어야 하는데, 이렇게 되면 사용하지 않는 데이터들도 항상 함께 조회해야 하며, 이는 성능상 좋지 않습니다. 이런 비효율적인 부분을 JPA가 보완해 주는 것입니다.
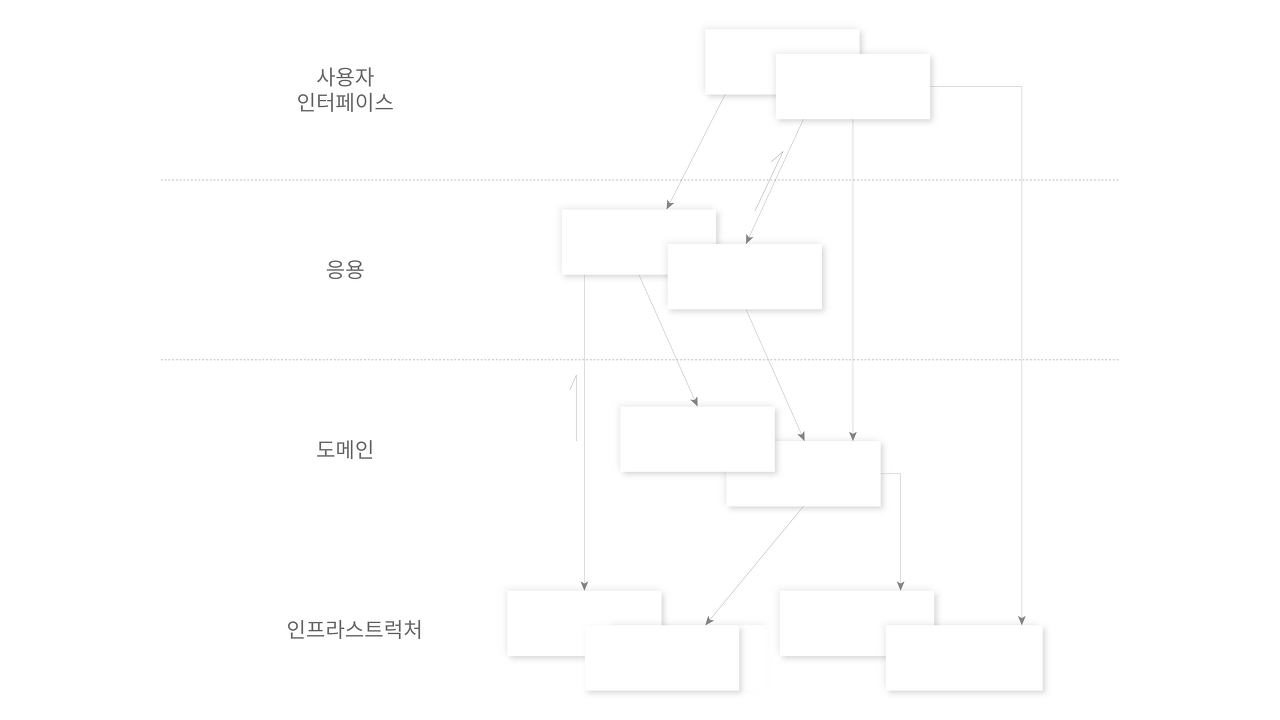
하지만 이를 사용하는 개발자입장에서는 추가쿼리가 어디서/왜 발생하는지 모른다면, 기껏 찾아온 데이터에서 또 추가쿼리가 발생하는 제약사항이 존재한다면 기존에 해결하려던 문제보다 JPA 개념을 더 학습해야 합니다. 배보다 배꼽이 커지는 상황이 발생하는 것이죠. 이런 복잡성과 추가쿼리가 JPA를 사용하며 느꼈던 두 번째 단점이었습니다.
3. 자동화
세 번째는 너무 많은 부분을 자동화 해 준다는 단점이 있습니다. 사실 이는 장점으로 볼 수도 있는 부분인데, 처음 개발공부를 하거나 혹은 잘하는 개발자가 이를 활용할 때는 이보다 편리한 기능이 없습니다. 하지만 학습하는 입장에서는 너무 많은 부분이 추상화 돼 있으므로 구현체가 무엇인지, 어떤 원리로 동작하는지 등을 파악하기 어렵습니다.
JPA가 모든 쿼리를 만들어주기 때문에 개발자가 쿼리 한 줄 안짜더라도 원하는 객체를 찾을 수 있습니다.
예를 들어, JpaRepository는 메서드의 네이밍에 맞춰 쿼리를 실행해주는 Query Method를 제공합니다.

이는 아래 순서로 실행이 되며, 그 구현체로 SimpleJpaRepository를 사용하고 있습니다. 하지만 이런 동작 과정은 모두 가려진 채 우리는 JPA가 작성해 주는 쿼리만 사용하게 되며, 에러가 났을 때 이를 디버깅하기가 매우 까다로워집니다. 따라서 이런 너무 많은 추상화, 자동화가 JPA를 사용하면서 느꼈던 세 번째 단점이었습니다.
- JpaRepositoryFactory를 통해 그에 대한 프록시 생성
- Query Method가 호출되면 프록시는 SimpleJpaRepository에 역할을 위임.
- SimpleJpaRepository는 QueryLookupStrategy을 통해 쿼리를 조회
- CreateIfNotFoundQueryLookupStrategy가 PartTreeJpaQuery로 메서드를 분석 및 쿼리 생성
- 쿼리 실행
4. JPA에 대한 의존성
마지막으로 JPA가 제공하는 기술에 의존하게 된다 는 점입니다. 즉, 엔티티=도메인 모델 이 된다는 점인데요, 엄밀히 말하면 도메인 모델은 영속 모델과 다릅니다. 도메인 모델은 특정 도메인을 개념적으로 표현한 것인데, 이를 바로 코드로 옮길 수는 없으므로 구현 기술에 맞는 구현 모델이 필요합니다. 따라서 우리는 클래스를 만들고 JPA에서 제공하는 @Entity를 붙여 도메인 모델을 엔티티로 나타내게 됩니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
// JPA 엔티티는 도메인 모델의 구현체가 됩니다.
@Entity(name = "post")
class PostJpaEntity(
@Id
@Column(name = "post_id")
@GeneratedValue(strategy = GenerationType.IDENTITY)
private var _postId: Long? = null,
@Column(name = "user_id")
val _userId: Long,
@Column(name = "place_id")
private var _placeId: Long,
......
) : BaseEntity()
이렇게 되면 도메인 모델이 엔티티(구현모델)가 되고 엔티티의 제약이 도메인 모델의 제약이 되는 문제가 발생 합니다. 즉, JPA의 기술적인 요소에 많이 얽매이게 되는 것인데요, 대표적으로 엔티티나 값 객체의 경우 반드시 기본생성자가 필요한 경우가 있겠습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
// JPA 엔티티는 도메인 모델의 구현체가 됩니다.
@Entity(name = "post")
public class PostJpaEntity extends BaseEntity {
@Id
@Column(name = "post_id")
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Embedded
var _title : Title,
......
// 반드시 필요한 기본 생성자
protected PostJpaEntity() {
}
}
1
2
3
4
5
6
7
8
9
10
11
12
@Embeddable
public class Title {
private String title;
// 반드시 필요한 기본 생성자
protected Title(){
}
......
}
물론 도메인 모델과 영속 모델을 분리해서 이를 해결하는 방법이 있습니다. 하지만 이는 추가적인 매핑 작업이나 트랜잭션에서 고려할 사항이 훨씬 많기 때문에 설계의 복잡성이 올라갑니다.
1
2
3
4
5
6
7
8
9
// 순수 자바/코틀린 코드로만 구현한 도메인 모델
class Post private constructor(
val postId: Long,
val userId: Long,
private var _placeId: Long,
......
)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
// 도메인 모델에 대응되는 영속 모델
@Entity(name = "post")
class PostJpaEntity(
@Id
@Column(name = "post_id")
@GeneratedValue(strategy = GenerationType.IDENTITY)
private var _postId: Long? = null,
@Column(name = "user_id")
val _userId: Long,
@Column(name = "place_id")
private var _placeId: Long,
......
) : BaseEntity()
이는 멀티 모듈로 구성할 때도 많은 제약을 발생시키는데, 멀티 모듈에서는 모듈간 의존관계가 생깁니다. 모듈 간의 의존 관계는 클래스 간의 의존관계보다 범위가 넓고, 복잡할 때가 많은데 JPA를 사용하면 항상 엔티티, JpaRepository, 데이터베이스에 대한 의존성을 함께 고려해야 하므로 고려할 점이 더 많아집니다.
1
2
3
4
5
6
7
8
9
dependencies {
// 도메인 모듈, 데이터베이스 모듈에 대한 의존성
implementation(project(":swith-me-domain"))
implementation(project(":storage"))
......
}
물론 이는 어떻게 멀티 모듈을 구성하는지에 따라 다르기 때문에 ‘이런 이슈가 있을 수도 있다.’ 정도로만 이해하고 넘어가셔도 괜찮습니다.
그 외에도 인덱스를 강제로 태우는 Force Index를 사용할 수 없는데요, 이런 부분은 Jdbc를 이용해 SQL을 사용해야 합니다. 이런 엔티티에 가해지는 제약이 도메인 모델의 제약이 되는 점이 JPA를 사용하며 느꼈던 마지막 단점이었습니다.
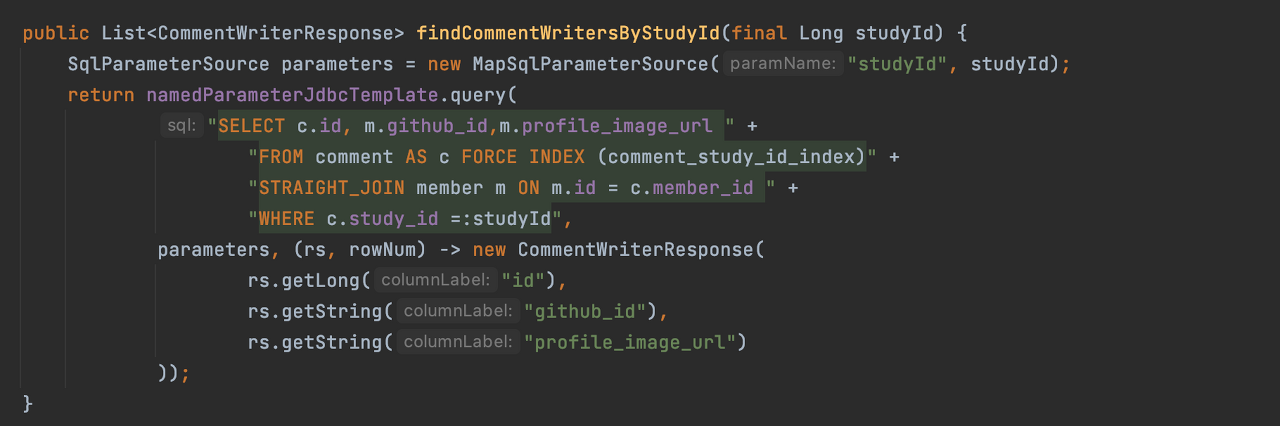
5. 정리
정리해 보면 JPA는 관계형 데이터베이스와의 패러다임 차이로 인한 많은 학습 분량, 복잡성과 추가쿼리, 많은 자동화, JPA에 대한 의존성이라는 단점이 존재합니다. 물론 JPA를 사용했을 때의 이점이 단점보다 크기 때문에 많은 사람이 이를 사용하지만, 해당 기술에 어떤 단점이 있는지를 명확히 파악하고 있는 것은 중요하다고 생각합니다.