
프로젝트에서 ETag를 적용하며 겪었던 점에 대해 간략하게 정리해보겠습니다. 학습 과정에서 작성된 글이기 때문에 잘못된 내용이 있을 수 있으며, 이에 대한 지적이나 피드백은 언제든 환영입니다.

1. ETag를 사용한 이유와 성능
캐시는 하드웨어, 운영체제, 네트워크, 애플리케이션, 데이터베이스 등 다양한 곳에서 사용할 수 있습니다. 웹에서는 일반적으로 네트워크, 애플리케이션, 데이터베이스, 인메모리 데이터베이스 등의 캐시를 사용하는데, 이중 ETag는 네트워크 캐시로 나머지 보다 훨씬 빠른 성능을 자랑합니다. 이는 서버 내부까지 들어가지 않고 HTTP 헤더만 검증해서 값을 반환하기 때문입니다.
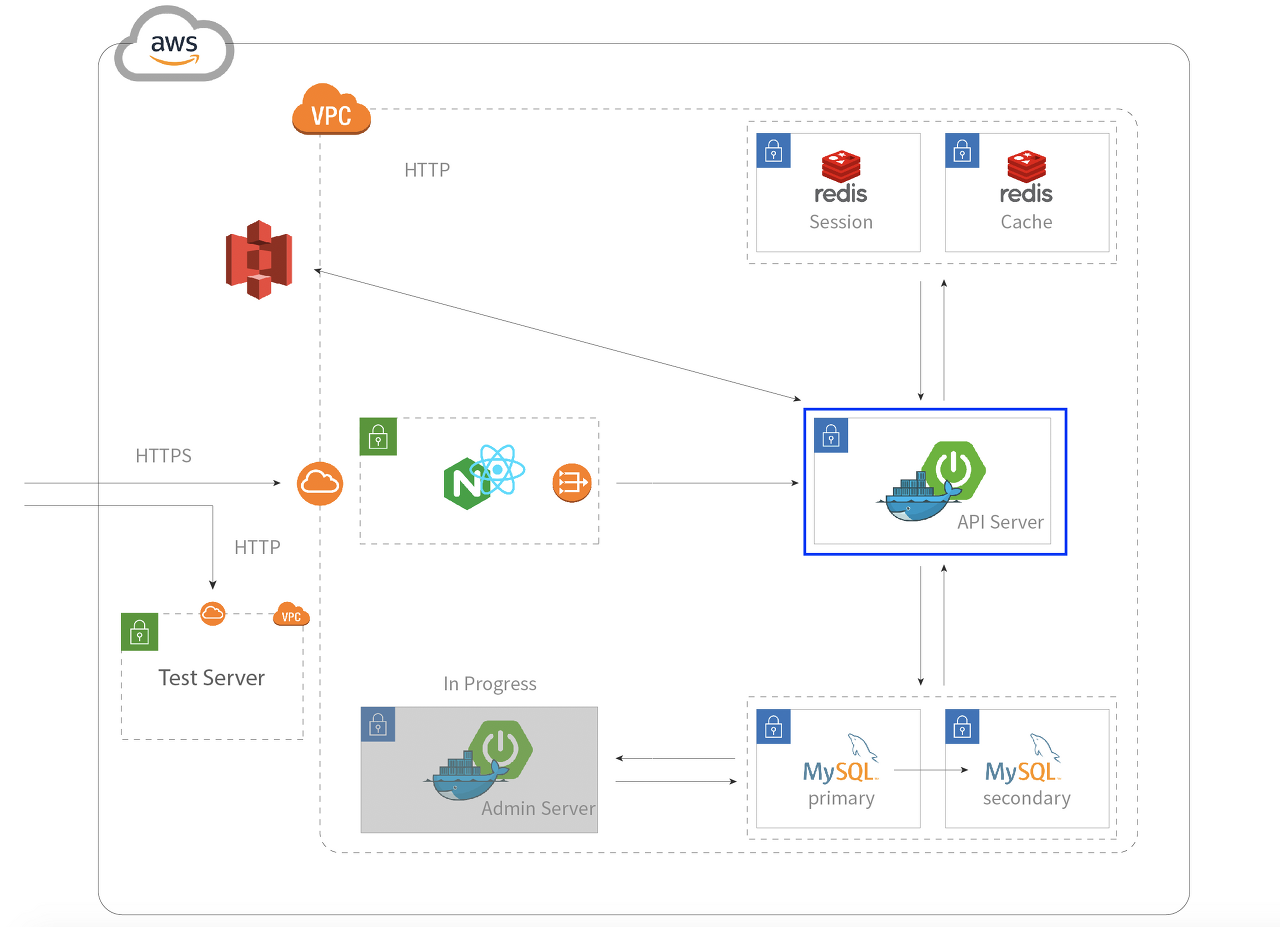
애플리케이션이나 데이터베이스 캐시는 아무리 빠르다고 해도 값을 얻기 위해 서버 내부로 들어가서 값을 받아오기 때문에 일반적으로 네트워크 캐시보다 느릴 수밖에 없습니다.
서버에서는 지역, 스터디 진행방식 등 몇 가지 잘 변경되지 않는 데이터를 사용하고 있었는데, 이런 API들에서 불필요한 호출이 여러 번 일어날 필요가 없다고 판단했습니다. 따라서 여기에 ETag를 적용하기로 했고, 이를 통해 아래와 같이 정말 빠른 조회가 가능해졌습니다.
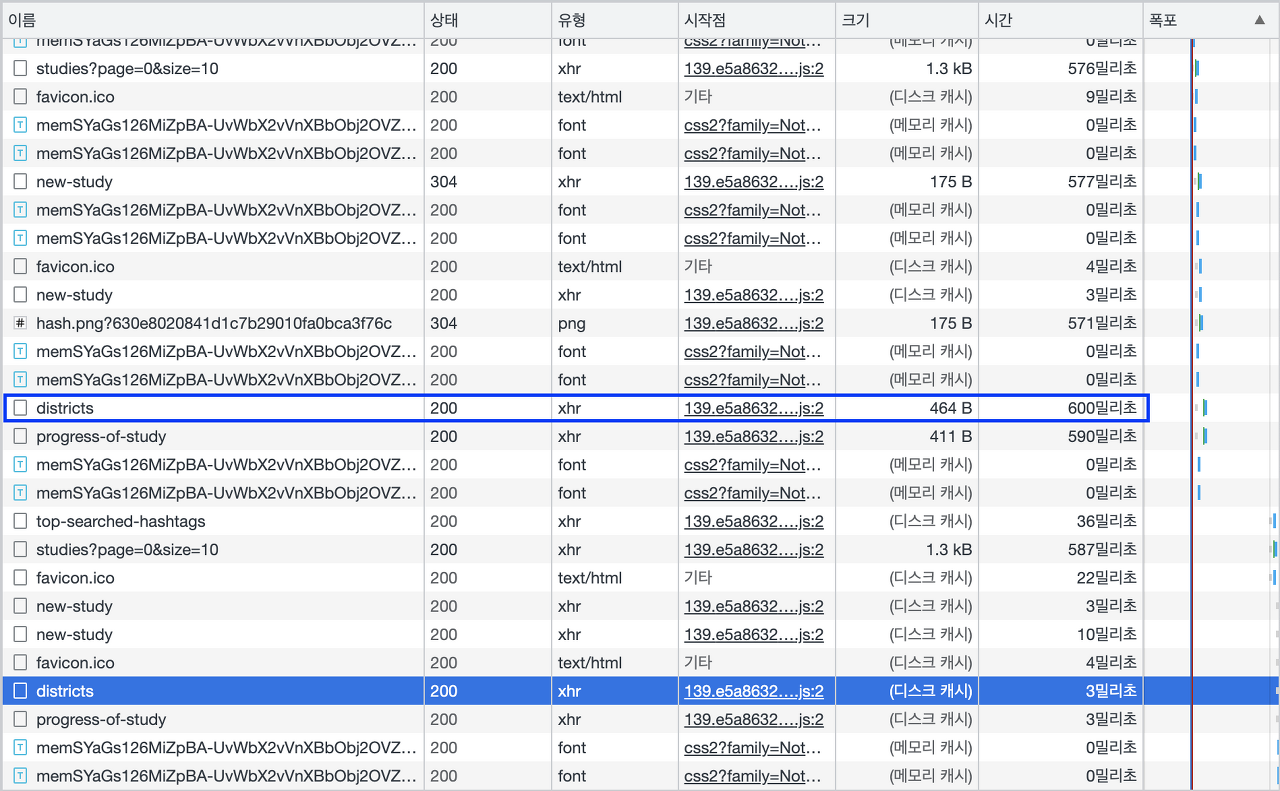
최초로 데이터를 받아올 때는 600m/s가 걸리지만 ETag를 적용하면 3m/s 만에 데이터를 받아오는 것을 볼 수 있습니다.
2. 발생한 이슈
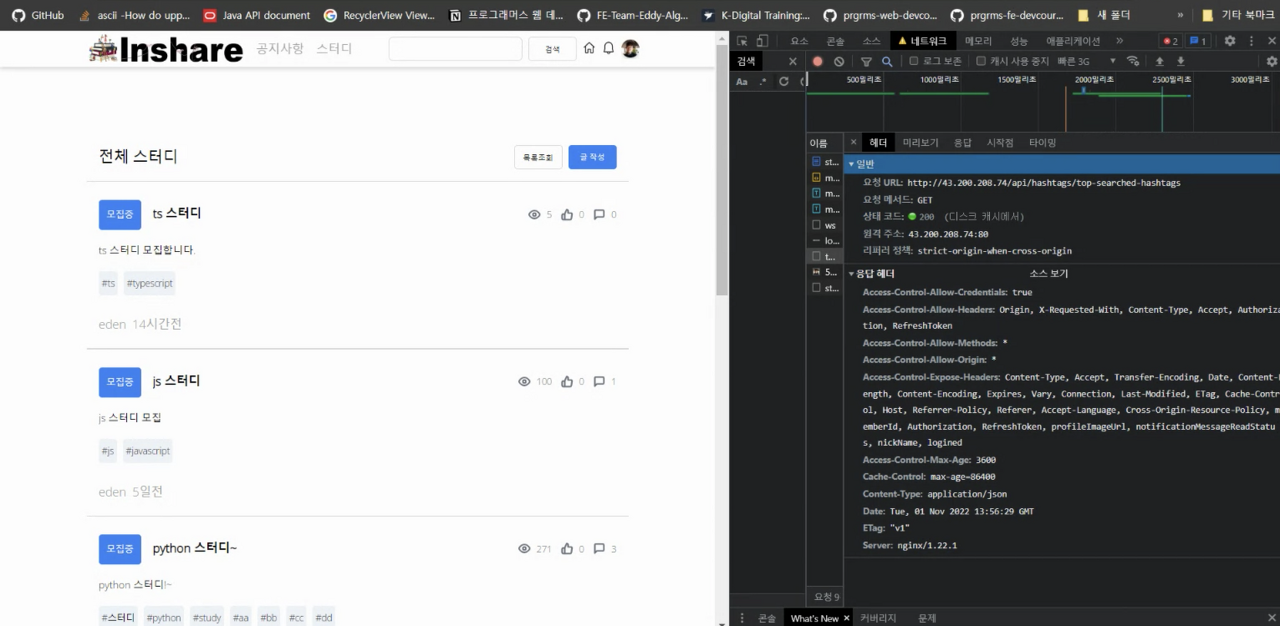
ETag는 캐시로 사용하다보니 아래와 같이 데이터가 변경되어도 캐시가 남아있는 이슈가 발생했습니다. . 최초 데이터를 받아올 때 빈 배열 데이터를 받아와서 이후 데이터가 갱신됐음에도 불구하고 값을 받아오지 못하는 상황입니다.
원래 대로라면 아래와 같이 자주 사용되는 해시태그가 상단에 나타나야 하지만 최초에 데이터를 받을 때 빈 배열을 받아왔기 때문에 서버가 복구되고도 제대로 된 데이터를 받아올 수가 없는 것입니다.

심지어 API 서버를 내려도 캐시가 남아있는 것을 볼 수 있습니다. 아래는 API 서버를 강제로 종료한 후 프론트 서버만 켜놓은 상태인데, 기존의 캐시 때문에 조회되어서는 안 될 데이터가 로딩되고 있는 상황입니다. 별도로 Query 모델을 분리하지도 않았습니다.
이를 위해서는 ETag에 버전을 붙여 재배포를 하거나 앞단 서버에서의 추가적인 조치가 필요합니다. 아니면 현재 남아있는 캐시가 계속해서 반환되기 때문에 똑같은 결과만 받을 수 있습니다.
3. 정리
ETag를 사용하게 되면 한 번 받아온 캐시를 브라우저에 저장하기 때문에 Last Modified Since가 만료되지 않았다면, If-None-Match 헤더가 일치한다면 추가적인 데이터를 받아올 필요가 없습니다. 따라서 압도적으로 빠른 속도로 데이터를 조회할 수 있습니다. 하지만 브라우저에 캐시가 남아있으므로 이를 제거하기 위해서는 서버를 재배포하거나 일정 시간을 기다리는 등 별도의 조치를 해주어야 합니다. 따라서 정말 변할 가능성이 작으면 이를 사용하도록 합니다.